Dominic is the CEO of Lawpath, dedicating his days to making legal easier, faster and more accessible to businesses. Dominic is a recognised thought-leader in Australian legal disruption, and was recognised as a winner of the Australian Legal Innovation Index and recently a winner of the LexisNexis 40 Under 40 (APAC).
In a recent report documenting the advances in Artificial Intelligence, Goldman Sachs estimated that over 300 million jobs could be displaced by AI, and more specifically that up to 44% of legal tasks could be completed using AI. Whether you agree with this assessment or not, it’s clear that AI and easily-accessible Large Language Models will have a big impact on the legal industry.
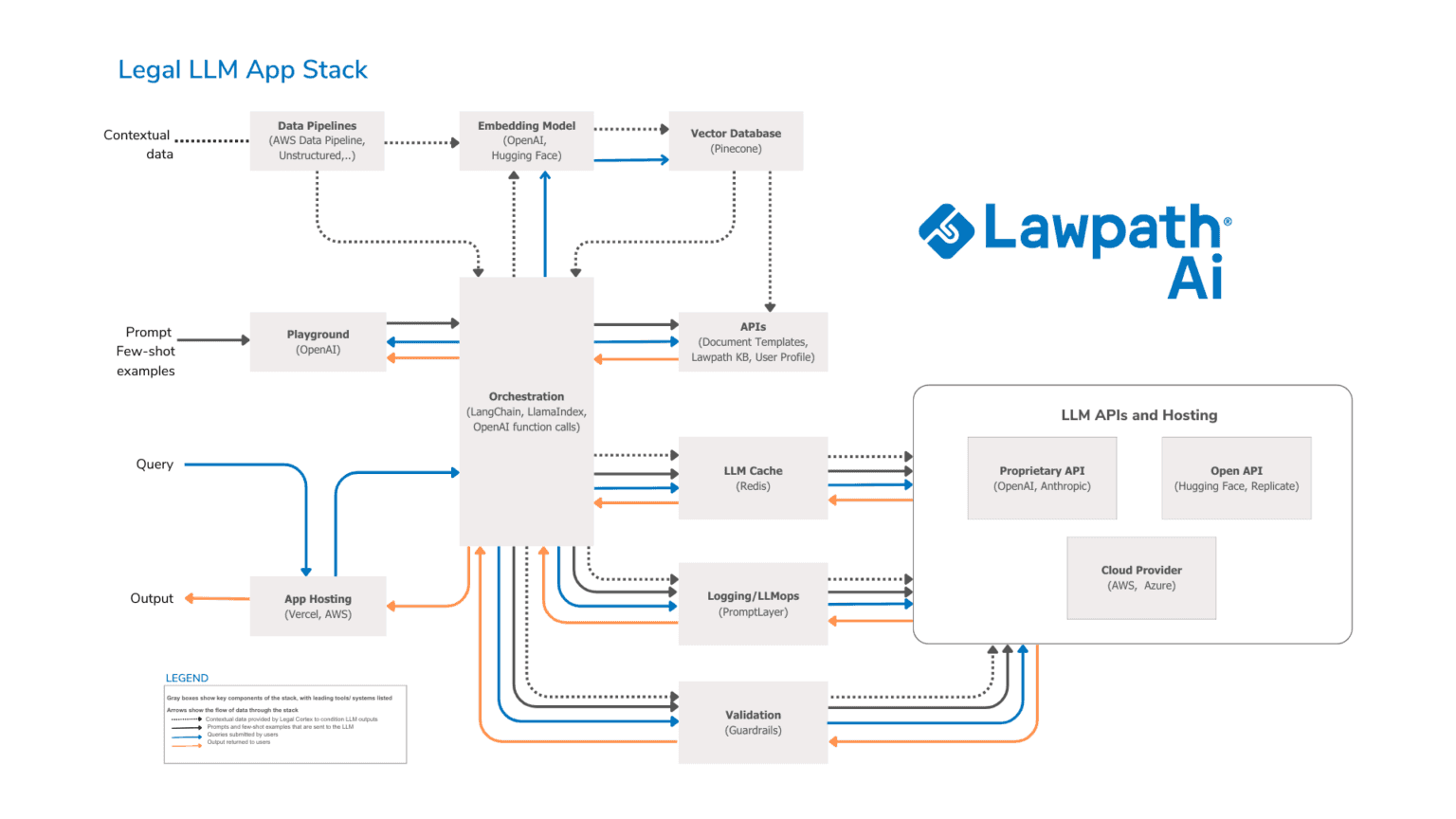
Inspired by the work of Matt Bornstein and Rajko Radovanovic at a16z and their article Emerging Architectures for LLM Applications, this post builds on the original and attempts to set out the methods and architecture that can be used to build an LLM operating system for the legal industry. The technology stack set out below is still in its early stages and may undergo changes as the underlying technology advances. However, we hope that it will serve as a useful reference for developers currently working with LLMs in the legal space.
Here is a list of common LLM tools and the ones selected for our Legal LLM use case.
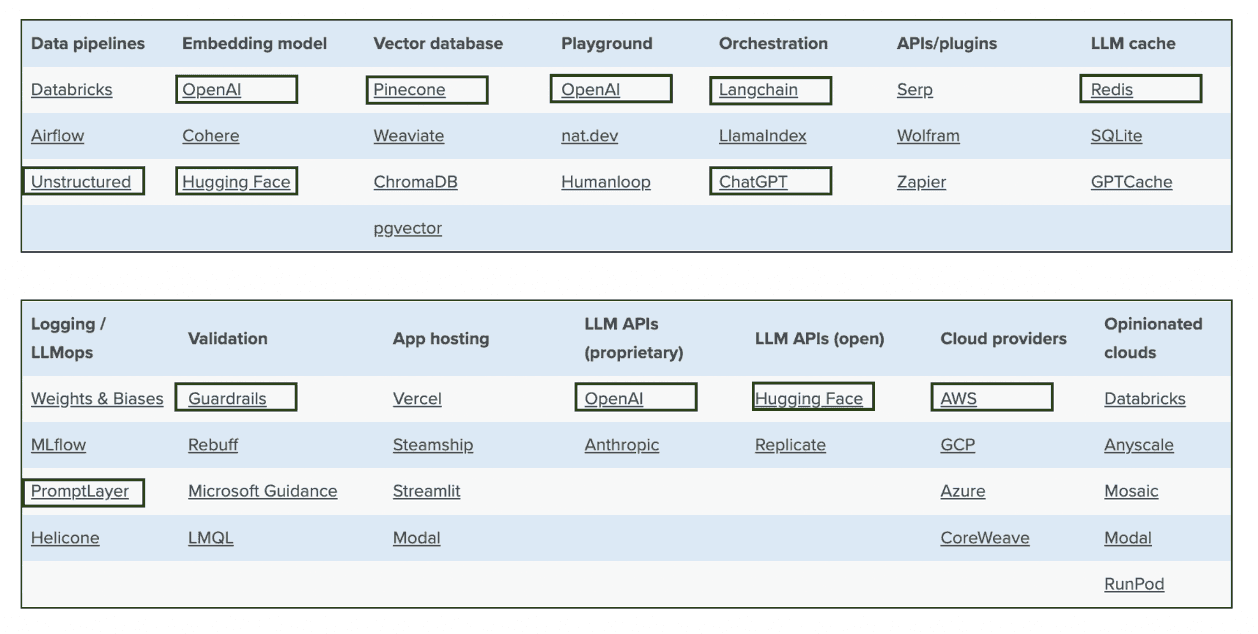
*source: https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/
In-context learning
Contrary to popular belief, you do not have to be an AI expert or machine learning engineer to build and harness the power of AI. There are many ways to build with LLMs, including training models from scratch, fine-tuning open-source models, or using hosted APIs. The stack and methods we have chosen to use are based on in-context learning, an increasingly common design pattern.
The core idea of in-context learning is to use LLMs off the shelf (i.e., without any fine-tuning), and then control their behaviour through clever prompting and conditioning on private “contextual” data.
To expand further on this, contextual learning eliminates the need to ‘train’ or input vast quantities of data into foundation models like GPT-4 or BARD. Instead, it offers the capability to govern and transmit only the information that is relevant to the immediate query.
Given the privacy concerns, costs, and dynamic nature of data, alongside the extensive ML expertise and resources required, fine-tuning may not always be the optimal approach, particularly when handling sensitive or confidential data. Furthermore, it’s essential to consider that, when attempting fine-tuning, a specific piece of information typically needs to surface approximately 10 times in the training set before a language model can retain it.
However, with the advent of modern foundation models that boast a large enough context window, the capacity to accommodate a significant volume of data has been greatly enhanced. This progress allows the use of contextual learning and vector embeddings—a highly specialised tool that will be further discussed below—to process data with increased efficiency, privacy, and ease. In the realm of legal compliance, this approach facilitates the usage of vector embeddings, the context of which can be interpreted exclusively by your specific system. This unique feature establishes a strong defensive line for any confidential or privileged information. Crucially, when navigating relatively smaller datasets, supplementing each prompt with any necessary context information often outperforms the conventional fine-tuning of a language model.
Once a Language Learning Models (LLMs) is primed with this context data—passed as a system or user message via the prompt API call—the system enables a ‘conversation’ with the data and allows for summaries upon request.
Despite the fact that the provided context is now used to build responses, it’s important to note that the underlying model has not truly ‘learned’ this context as its parameters remain unaltered. This process, thus, temporarily grounds and personalises the LLM, empowering it to respond to prompts not seen in the pre-training data.
This innovative approach opens up important use cases for LLMs, making them more accessible and allowing legal practitioners to uphold their privacy commitments.
The three components of an ‘in-context’ workflow are:
- Data preprocessing / embedding / database: This phase encompasses the preservation of private data, whether in an unstructured or structured format, for future retrieval. Conventionally, documents are divided into segments, and a Language Model (LLM) is used to create vector embeddings from these segments. These embeddings are then stored in a vector database, a specialised type of database designed to manage such data. This database is further segmented into relevant namespaces, which aid in establishing context boundaries. From a systems perspective, the vector database forms the most crucial part of the preprocessing pipeline. It bears the responsibility of efficiently storing, comparing, and retrieving potentially billions of embeddings, also known as vectors. For this purpose, we employ the use of Pinecone.
- Prompt construction/retrieval: A request is formulated in response to user interaction. This request is then transformed into a vector embedding and dispatched to the memory vector store to fetch any associated data. This pertinent data, along with the user request and any context extracted from the context store, is incorporated into the prompt that is subsequently directed to the Language Learning Model (LLM). The prompts and responses generated within the current session are converted into vector embeddings and stored within the memory vector store. These stored embeddings can be recalled whenever they bear semantic relevance to future LLM interactions. At this juncture, orchestration frameworks like LangChain become crucial, serving two key functions: retrieving contextual data from the vector database and managing memory across multiple LLM interactions. This entire process ensures that the system not only responds appropriately to user interaction but also that it continues to evolve and refine its responses with each subsequent interaction.
- Prompt execution/inference: The prompts and contextual data are submitted to the foundation models for inference (OpenAI is the leader among language models, gpt-4 or gpt-4-32k model). Currently we are using gpt-3.5-turbo-16k-0613: It’s ~50x cheaper and significantly faster than GPT-4 and provides a large enough context window to generate high-quality responses which are relevant to the user request.
Finally, the static portions of LLM apps (i.e. everything other than the model) also need to be hosted somewhere. We use AWS to host all of our LLM Apps.
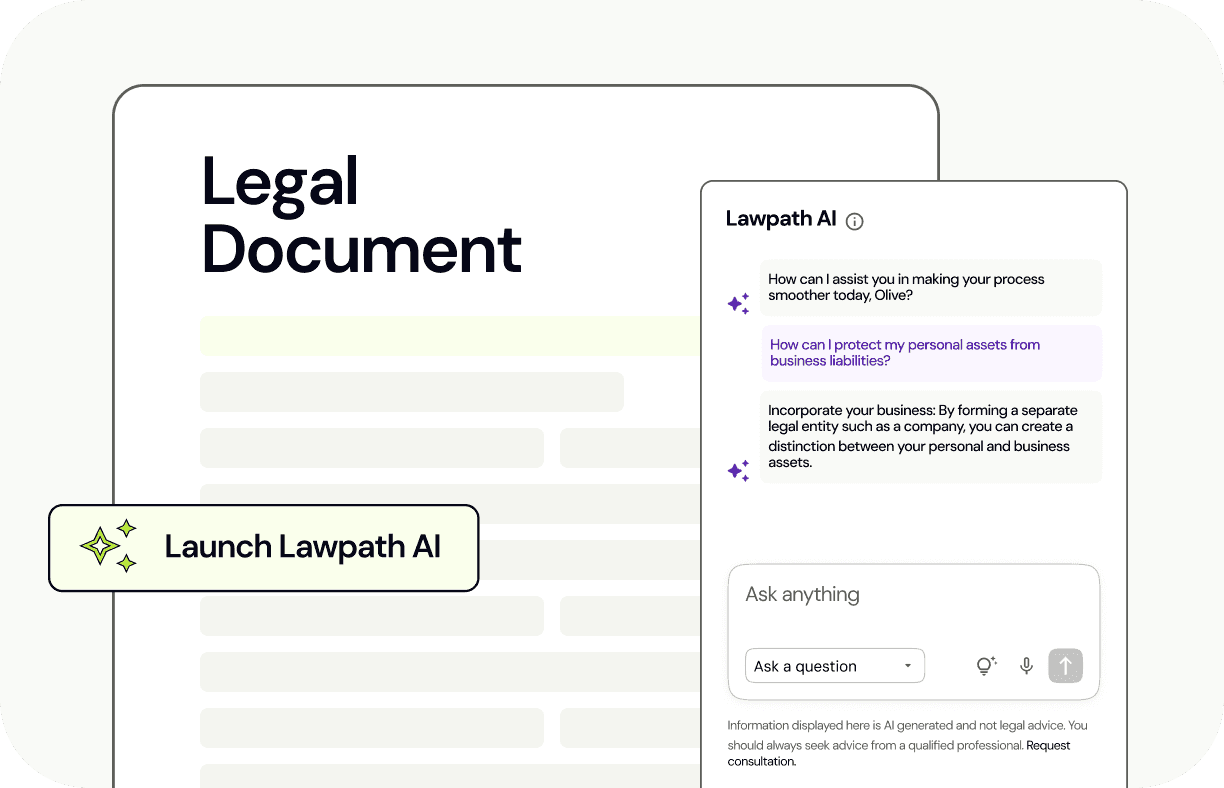
Lawpath AI
Over 87% of small businesses globally are unable to access legal services. Lawpath’s mission is to make the workings of the law fairer and more accessible to small businesses. Technology is a key piece of this puzzle, as it allows us to create interfaces through which our users can confidently complete legal tasks themselves. So far, such interfaces have been used by customers to start businesses, meet regulatory compliance requirements, manage complex legal workflows, auto-populate legal contracts, and obtain on-demand legal advice. With over 350,000 businesses using our platform and over 25 million datapoints, Lawpath is ideally placed to unlock the power of LLM technology to improve legal services.
What should be the structure of my new business? What type of trademark should I obtain? What clauses should I include in my employment agreement? How do I terminate my lease? What cancellation process is appropriate for my software service? Should I sign this document?
Until recently, only a lawyer could be trusted to answer these questions. Technology has allowed us to reposition the user, or client, as the key driver and decision-maker in their interactions with the law. The power of LLMs, as outlined above, allows users to educate themselves and to efficiently access the answers to their important questions.
This can be achieved at scale, in an increasingly tailored manner. Lawpath AI combines specific data linked to a user and then overlays it with data from users with similar characteristics to produce the most appropriate guidance. Let’s say you’re growth-stage SaaS start-up with 20 employees located in Sydney. We will identify datapoints across matching categories and bring you the information that was most useful to users in those categories, such as the legal documents they used, the types of disclosures they made to ASIC and the ATO, and the pain points which prompted them to seek legal consultations.
Deep beneath the layers of the Lawpath application, our orchestration framework – the Lawpath Cortex – forms the nerve centre of Lawpath AI. It chains all the elements of the stack together. Lawpath Cortex is crafted to deliver a personalised user experience, while ensuring absolute privacy. It’s a memory bank, context provider, and much more, all working to deliver a tailored service to each user.
What sets Lawpath’s LLM stack apart from the crowd is its unparalleled personalisation. It doesn’t simply churn out boilerplate legal advice. Instead, it crafts a bespoke legal journey for each user by cross-referencing user data on the platform and offering customised solutions, it’s like having a personal legal advisor on call 24/7.
Whether you’re a small-town business or an expanding tech powerhouse, Lawpath’s LLM stack is here to make legal processes less intimidating and more accessible. It’s not just about providing answers. It’s about empowering you with the tools to confidently navigate your unique legal terrain.
Key Features of Lawpath AI
Document Review – Review documents you have created or been asked to sign using our review feature. Identify issues with clauses and find the answers you need from complex documents.
Ask – Ask questions and get legal answers specifically tailored to your business and its attributes.
Simplify – Never sign an agreement you don’t understand again. Lawpath AI provides clear and concise explanations of legal documents, making it easier for you to understand complex clauses and content.
Translate – You can now translate legal documents into 31 languages, ensuring that you can read and understand legal documents in a language you are comfortable with.
Recommend/Alerts – Not sure what to do next? You will receive personalised next steps and automatic alerts for key dates, unfair clauses, and much more.
Conclusion
The legal industry is ripe for disruption with the advent of advanced language models and AI. It is clear that those who embrace this technology will have a competitive advantage in the marketplace, and be better positioned to drive positive change for users. The LLM stack outlined in this article is just one possible architecture for building an LLM operating system for the legal industry. The possibilities for LLMs are endless and we are excited to see what the future holds as these technologies continue to advance.
Whether you’re a business looking for a new way to complete your legal needs, a legal enthusiast looking to work at the cutting edge of legal tech, or an investor who believes the $1 trillion legal industry is ready for disruption, come take a look at what we’re building at Lawpath AI.